Game Server Monitoring
I was brought on to the TF2Maps.net staff team to bring my technical expertise to help maintain and improve the state of our systems.
The first thing I did in order to get an idea of how the servers were used was to install some monitoring software.
Tools that have previously failed me
I've had previous experience with a bunch of different tools, but none of them I was really a big fan of, they all have annoying limitations. I've used all of these tools at one point in my career:
The TICK stack is nice except their dashboarding tool is really lacking in a lot of ways, and their query language is not as nice for more complex use cases. ELK stack has a huge amount of overhead to get it setup well, but a good ELK setup is defiantly really nice. Nagios is just... well... Nagios, not much needs to be said that has been said to death already. Cloudwatch I want to like, but its obviously AWS specific and it's dashboarding is really limited as well. Even pulling metrics from it into Grafana is still really hard to use meaningfully. Infact, as recently as 6 months ago, I tried to do just this but I couldn't find even a documentation page on their query syntax.
Enter Prometheus
For the longest time; I was confused at how Prometheus worked, and they way they explain its "no long term storage" thing I think turned me off for a long time on it.
I thought I'd give it a try on the recommendation of a co-worker and it being probably the only tool I haven't yet tried for monitoring.
Grafana cloud also has a free tier offering that was enough for me to test stuff out with!
The storage thing is basically just that they don't retain metrics forever and also don't offer any kind of highly available or redundant storage solution. This is fine for my use case, but may not be suitable for everyone.
What to track?
So I will be monitoring our 4 Team Fortress 2 game servers.
Currently they run on co-located hardware. 2 in New York and 2 in Frankfurt. Each server has its own distinct hostname (DNS resolvable), so I can use that as a "key" to filter by each instance.
Basically I just want to have some insight to what is going on the server when I'm not directly logged in and so we can analyze historical events like server crashes or moderation events.
Instance metrics
- CPU Metrics
- Memory Use
- Disk Space and IO
- Network IO, packet loss, bandwidth usage
Process metrics
- Is the srcds process even running?
- How long has the srcds process been running
Game Server stats
- Current player count
- Current level server is set to
- Histogram of player activity
- Histogram of levels played
How to gather metrics with Prometheus?
To my surprise, this is actually quite easy to do, every other tool I've used is very cumbersome to setup. Each of the buckets of metrics I want can be grabbed basically out of the box using Prometheus exporters. Here are the exporters I used:
- Node Exporter - Stats about the machine itself.
- Process Exporter - Stats about specific processes on the machine
- Srcds Exporter - Specific to srcds data like map name, player count, etc.
You basically give each one a config file to read a few variables like telling it how to find the process it needs to watch or information about the hostname and most importantly, the Prometheus instance to publish them to.
Now this is the part that was confusing for me at first. You need to run a local Prometheus on the server in order to publish / replicate the metrics to a remote one that does the actual aggregation. In this case, my local Prometheus published to the one hosted by Grafana Cloud.
On a small aside, I'll also say the Grafana Cloud docs are fantastic for setting this up and I had absolutely no issues getting going with it.
Below are snippets from my config files (node_exporter needs no config):
process_names:
- name: "srcds_linux"
exe:
- tmux
cmdline:
- new -d -s tf .*
options:
rcontimeout: 60s
cachetimeout: 15s
servers:
us.tf2maps.net:
address: 172.93.228.253:27015
rconpassword: ***password***
Logging Admin Actions
TF2 servers often run modding platforms that come with an ecosystem of plugins for doing administrative actions. One very popular platform is called SourceMod. Many of the built-in plugins will log important information like administrator actions to a log file that I can parse. Obviously logs are not like metrics that can be measured every minute, log files get new lines at random intervals, so it requires a different tool.
Thankfully, Prometheus has an answer to this! In order to scrape logs you have to run another service called Loki, which is advertised as "Prometheus but for logs". Grafana Cloud's free tier also comes with Loki access. Awesome!
To actually export to Loki, you need to run a Prometheus style exporter called Promtail.
Now, most people who know me know that I'm a wizard with Regular Expressions, though admittedly this one took me a while to get right. Whoever created this log format clearly did not intend for it to be parsed. (Aside: Lea Verou has a great RegEx testing tool that I highly recommend for this kind of task.)
Below is the full config I used to parse the SourceMod log files. (I would have really preferred JSON, but SourceMod has been around since before JSON was a thing)
---
pipeline_stages:
- match:
selector: '{job="sourcemod"}'
stages:
- regex:
expression: 'L (?P\d{2}\/\d{2}\/\d{4} - \d{2}:\d{2}:\d{2}): \[(?P.*\.smx)\] \"(?P[A-Za-z0-9\ ]+)<\d+><(?P\[U:[0-9]:[0-9]+\])><[\d\w]{0,}>" (?P.*)'
- labels:
plugin:
user_name:
steam_id:
- timestamp:
format: '01/02/2006 - 15:04:05'
source: timestamp
- output:
source: message
- match:
selector: '{job="sourcemod",plugin!~".*.smx"}'
stages:
- drop:
expression: ".*"
static_configs:
- labels:
job: sourcemod
__path__: /home/tf/tf/addons/sourcemod/logs/L*.log
This basically pulls out the timestamp, plugin name, user name, their steam id, and the actual log message.
Configuring Grafana
Now that we're collecting these stats, we need to display them! Prometheus does not have a tool for this themselves. The obvious choice here is Grafana, especially because they're very well integrated cloud free tier.
They have a really nice query builder / explorer to use. Very intuitive, and works well with both Prometheus and Loki out of the box. For most simple queries you can just click a few buttons and get what you want without having to even learn PromQL.
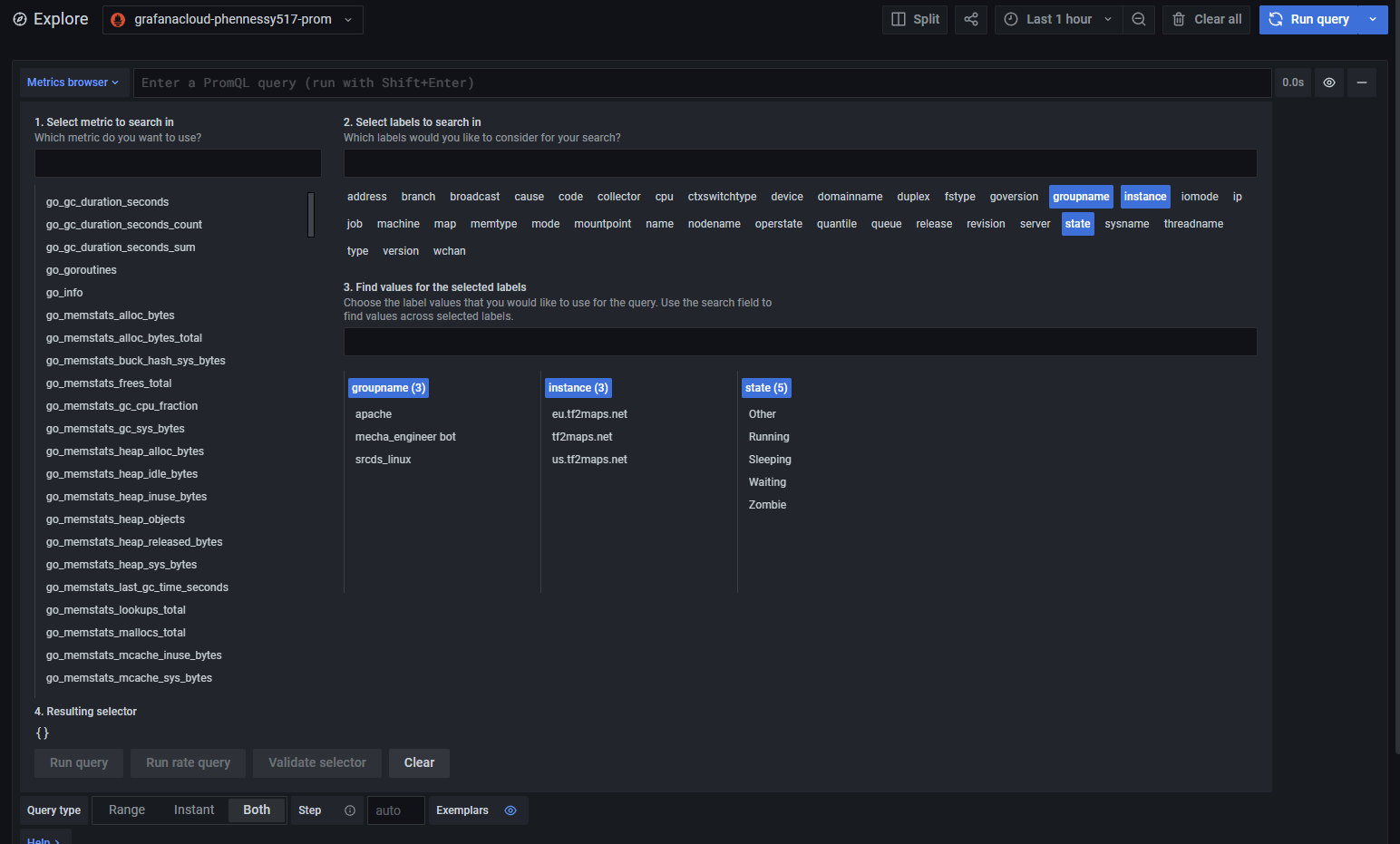{kind=link}
For the actual dashboard panels, I wanted to be able to filter by host. You basically just setup a dashboard variable and then you can use it as a variable in your queries:
srcds_playercount_humans{instance=~"$host"}
time() - namedprocess_namegroup_oldest_start_time_seconds{instance=~"$host"}
Most panels were very easy to setup. Infact most of them were just simple 1 liners just like the queries in the above code.
The Admin log required 3 transforms to display how I wanted. Filtering out unwanted messages, setting up the table fields, and a labels to fields transform.
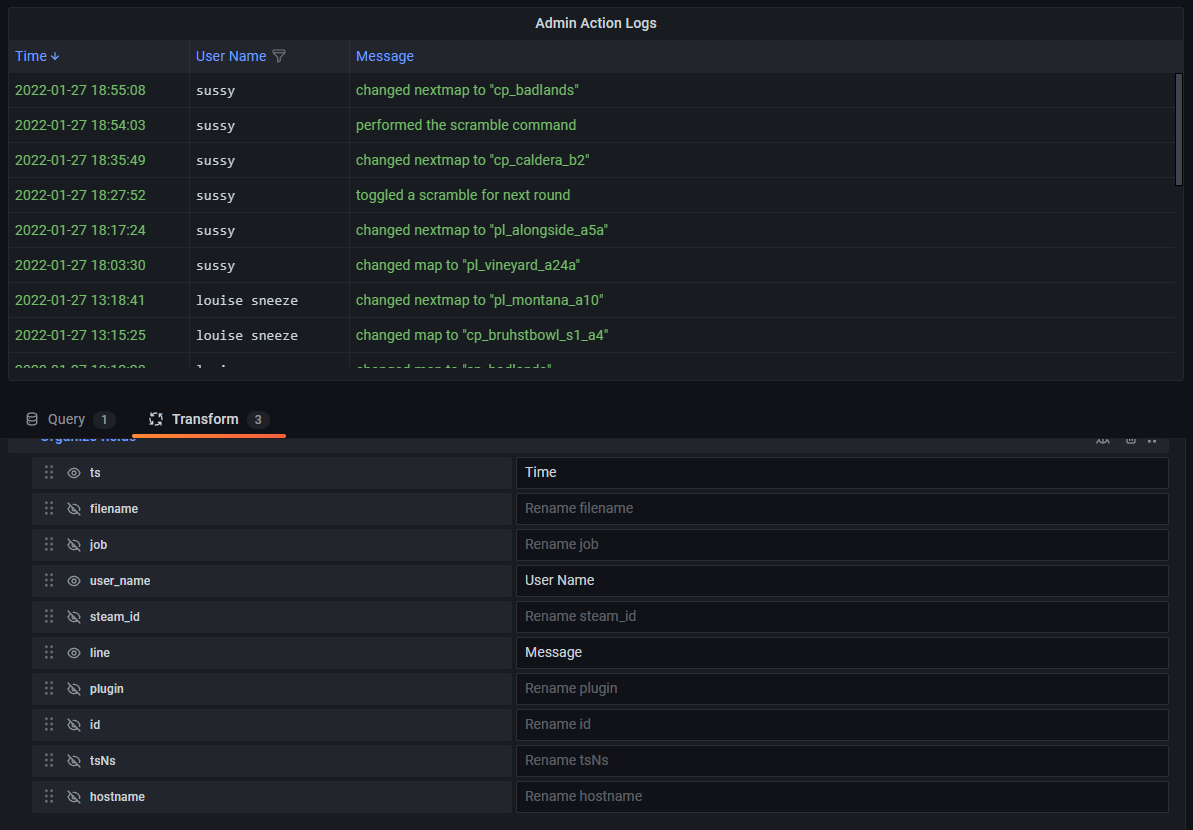{kind=link}
The panel that gave me the most trouble was the "Map activity" panel.
It is intended to show the history of the maps played. To get this to work, I had to use the deprecated version of their Graph panel, and setup a transform that converts a Prometheus label to the legend of the graph. If that sounds confusing, that's because it is. I basically monte carlo'd it into working.
¯\_(ツ)_/¯
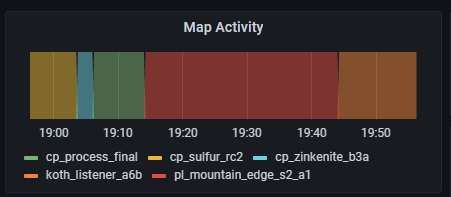{kind=link}
Full Dashboard
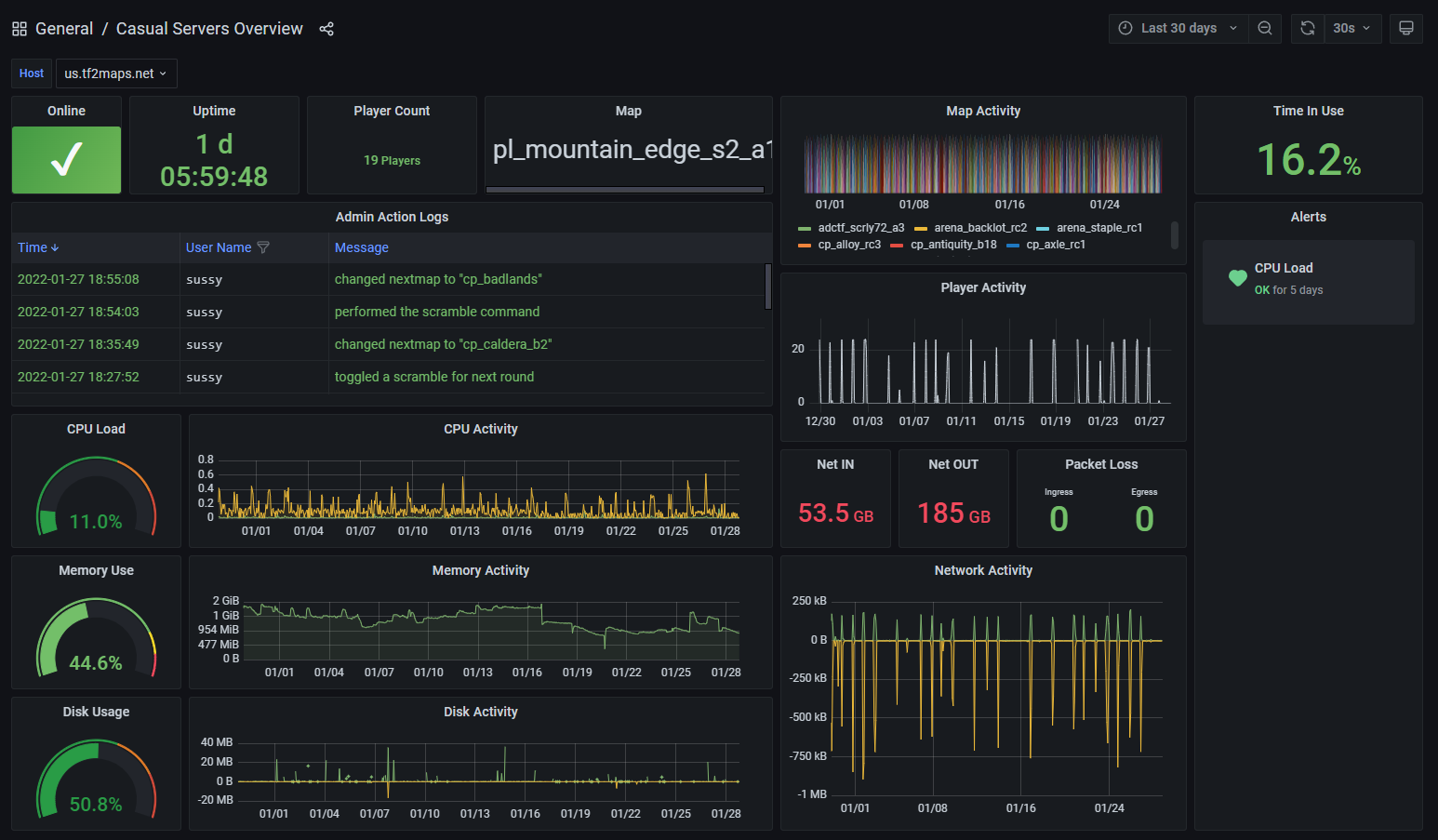{kind=link}
One thing to mention is that I also have a panel that is tracking the "time in use" stat. This is calculated by time spent running with at least 1 person connected; expressed as a percent. As you can see, we only actually use the servers very little compared to how long they run, and that's a generous number because simply having 1 player on the server doesn't really mean its "in use". This is part of a larger case I'm making for ad-hoc servers.
Takeaways from the data
Like I said above, I am tracking a number of stats so I can better determine our hardware needs in the future. Given our budget is extraordinarily low, we need to take as many optimizations as we can get.
The key takeaways I've gotton from this:
- The server is idle way too much. Ad-hoc servers would solve this problem
- Our bandwidth is higher than I expected
- Could be optimized by not having to keep a copy of a map on each server, but instead share a file system using something like EFS
- We're overprovisioned on CPU, RAM and Disk
- We never go above 10% cpu use, and we have 2 cores available. A VM with a single core should be more than enough.
- RAM use can get high at times, but that is a function of us running 2 srcds servers on the same VM. We could happily cut the provisioned RAM in half and be fine
- We just don't need a huge disk. We can do a better job of clearing out
.demfiles (game recordings) and clean out maps after they're been played in our map tests. Disks are fairly cheap though I suppose
Alerting?
Now that I'm tracking this information, can I meaningfully alert off of it?
Prometheus does have a tool called AlertManager for this task, but I must say this tool is very clunky to use, but even so I was able to get alerts working and publishing to our Discord server.
My big complaint with it is that you have to have a graph that is specific to a metric and setup as an "alarm graph" in order to alarm off of. In other words, I can't use my existing panels because alert manager doesn't like the $host filter. So I have to make a new dashboard just for alerts.
There is a big lack of customization for the data it shares with Discord and doesn't do a great job of keeping users informed when an alarm clears or is "acked". Also testing the whole alarming setup is really difficult and slow. It does feel like it was designed for a specific team and use case.
Honestly I'm probably better off using PagerDuty, but I'm not sure how to actually get the data out of Prometheus and into PagerDuty.
In summation
I have to say that I am pleasantly surprised at how easy this all was to get setup with. Prometheus and Grafana both have done a great job with their documentation and designing their tools for engineers. However their alerting solution could use some work in my opinion.
I'm happy with this level of success in this small effort because it's a prototype for things I may possibly bring into my work one day.
There is a synergy in solving problems for TF2Maps. Often at work I don't get as many opportunities as I like to just experiment with new tools. It make sense why we don't just constantly prototype new tools, but in doing so we do sometimes miss valuable setup's like this.
I would absolutely recommend the Prometheus + Loki + Grafana stack for anyone running game servers, not just Source servers.